接口自动化基本流程
前置条件
请先完成项目配置的相关配置
基本执行逻辑
接口自动化通过两个核心模块协同工作:
- 接口管理:集中管理所有接口信息和配置
- 测试用例:基于接口信息组装成完整的测试场景
全局变量配置
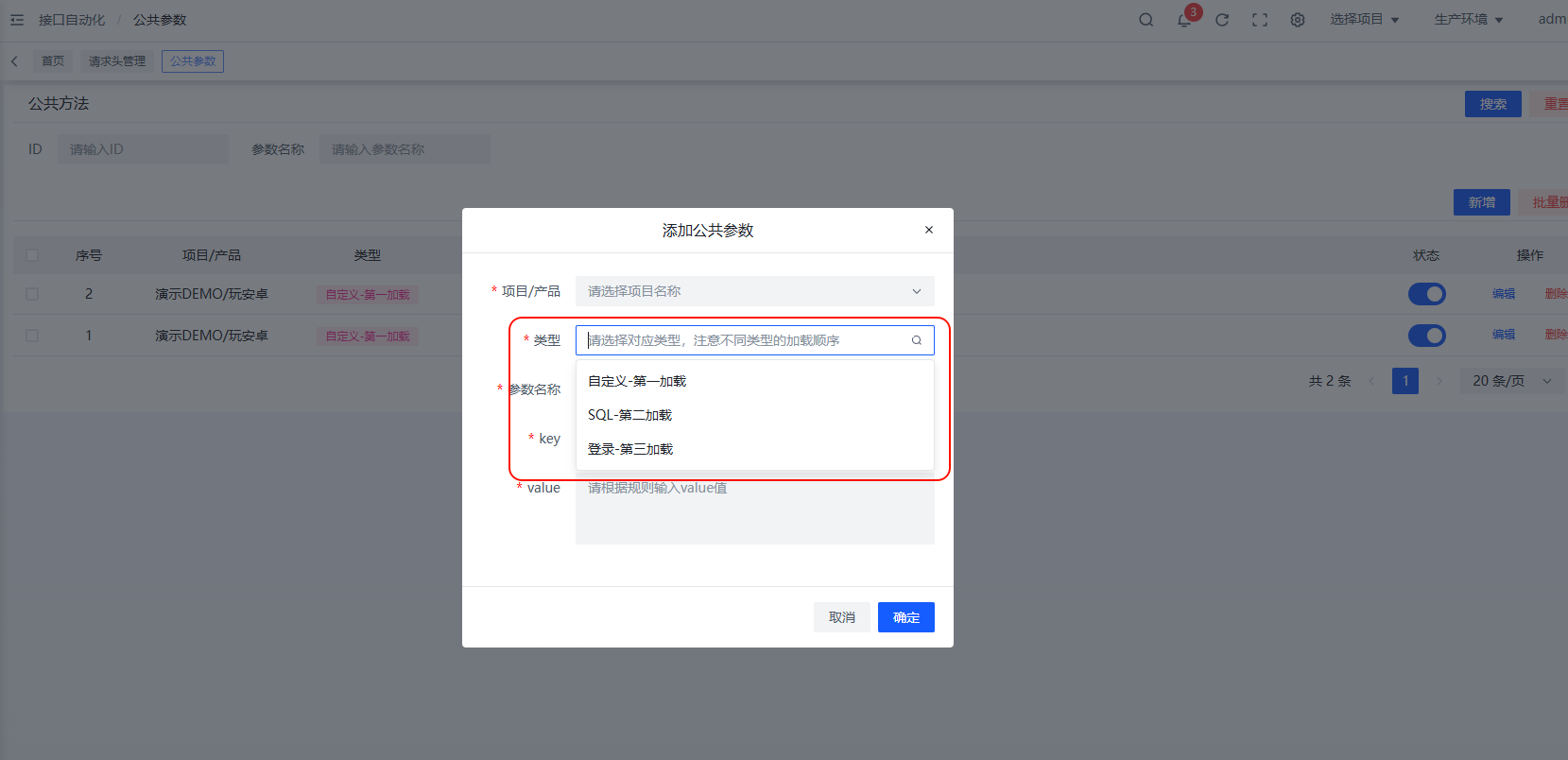
加载顺序说明
全局变量的加载顺序决定了数据覆盖的优先级。无论在接口管理、测试用例还是定时任务中执行,全局变量始终是第一个被加载到缓存中的。其中第一、二、三加载指的是全局变量内部的加载顺序。
第一加载 - 自定义变量
- 以key-value键值对的形式加载到缓存中
- 后续可以在全局变量中使用
- 其他加载阶段和接口管理、测试用例都可以使用这些变量
第二加载 - SQL查询
- 类似于JMeter的JDBC请求,同一个SQL查询必须确保只能返回一条数据
- 查询结果会按配置的key列表依次写入缓存
第三加载 - 登录接口
- 此阶段key字段无效,value字段需要填写登录接口的ID
- 系统会根据接口ID自动调用登录接口
- 主要用于初始化token或cookie,避免在每个用例中重复登录
请求头管理
根据项目实际需求配置请求头,可以创建多个请求头配置,使用时通过勾选启用。
在接口管理中使用
- 如果接口管理中的headers为空,则自动使用请求头管理中默认启用的headers
在测试用例中使用
- 如果用例的前置headers为空,则直接使用请求头管理中默认启用的headers
- 请求头的覆盖优先级如下:
- 用例接口级别的headers配置优先级最高,会覆盖用例级别的headers或默认headers
- 如果用例没有配置headers,则使用默认启用的headers
- 覆盖是逐条进行的,而不是全部替换
四、接口管理
- 用户可以在这里配置接口的信息,如:名称,url,请求的数据,固定的后置操作,等等
- 不过多介绍,这里只是先配置请求,类似postman调用一下
- 如果你们的产品是直接通过url拼接的,如:127.0.0.1:8000/get/info/123456 假设这个123456是一个查询的ID,那么这个在配置的时候需要直接使用全局变量方法,在后续的流程中补充进来
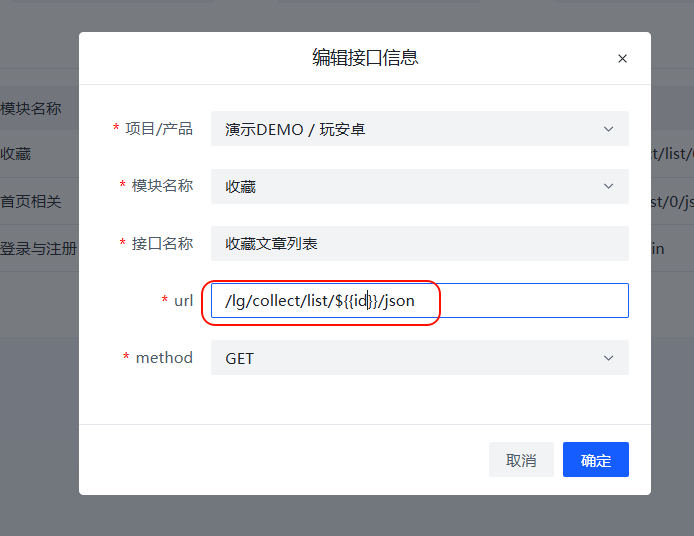
- api的调用,使用的是python的request库来完成的,如果发现无法调用的情况,自己可以使用request库来请求试试看
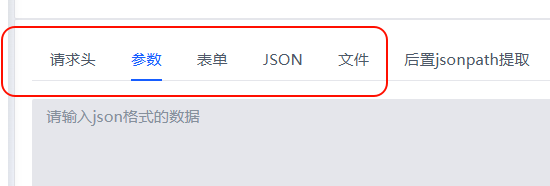
- 参数的填写:
- 参数:通过参数形式的接口,以json格式填写,示例
127.0.0.1:8000/get/info?id=123,则填写:{"id": "123"} - 表单:通过表单形式的接口,以json格式填写
- json:通过json形式的接口,以json格式填写
- 文件:
- 参数:通过参数形式的接口,以json格式填写,示例
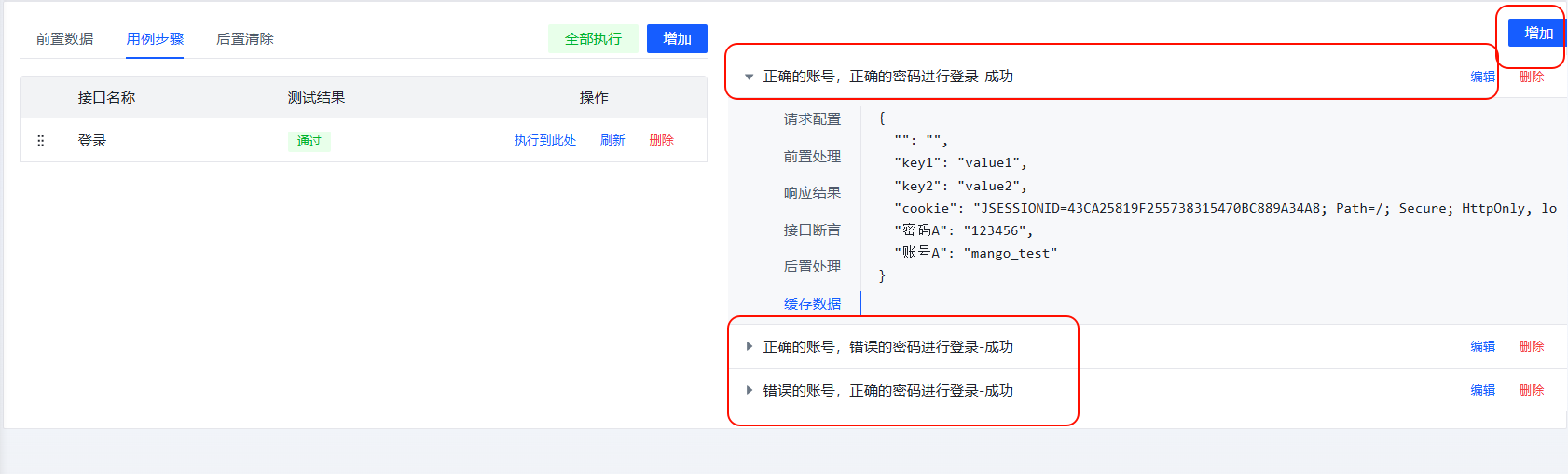
五、测试用例
用例支持选择接口管理中的接口来进行请求
用例的前置:
用例的后置:
- 只支持sql的执行操作
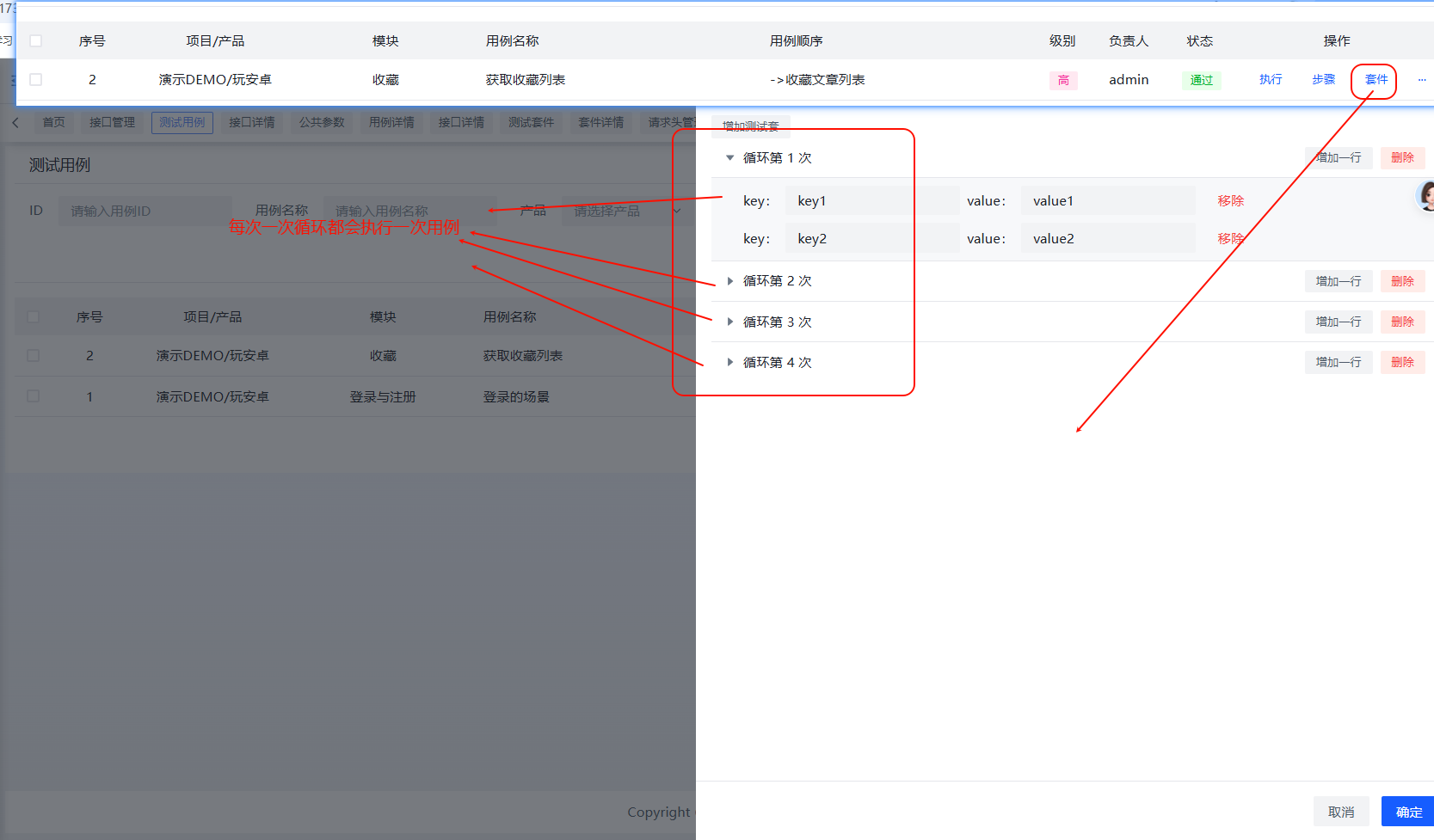
接口的执行: 前置后置
一个接口可以配置多个场景来执行
六、参数化
如果你有需求是配置一个用例,而传入不同的数据来达到不同的执行效果,那么可以使用参数化